
Ik was benieuwd: als je vijf bekende AI-chatbots dezelfde tien feitenvragen voorlegt, wie geeft dan de juiste antwoorden? Ik legde ChatGPT, Grok, Gemini, Perplexity en Claude tien controleerbare feiten voor — van het Kyoto Protocol tot het aantal manen van Jupiter — en vergeleek hun antwoorden met de geverifieerde feiten.
Let op: dit is een momentopname van specifieke versies (ChatGPT 4o, Grok 2024, Gemini 2.0, Perplexity Pro, Claude Sonnet 4.6). Nieuwere versies kunnen beter — of anders — scoren.
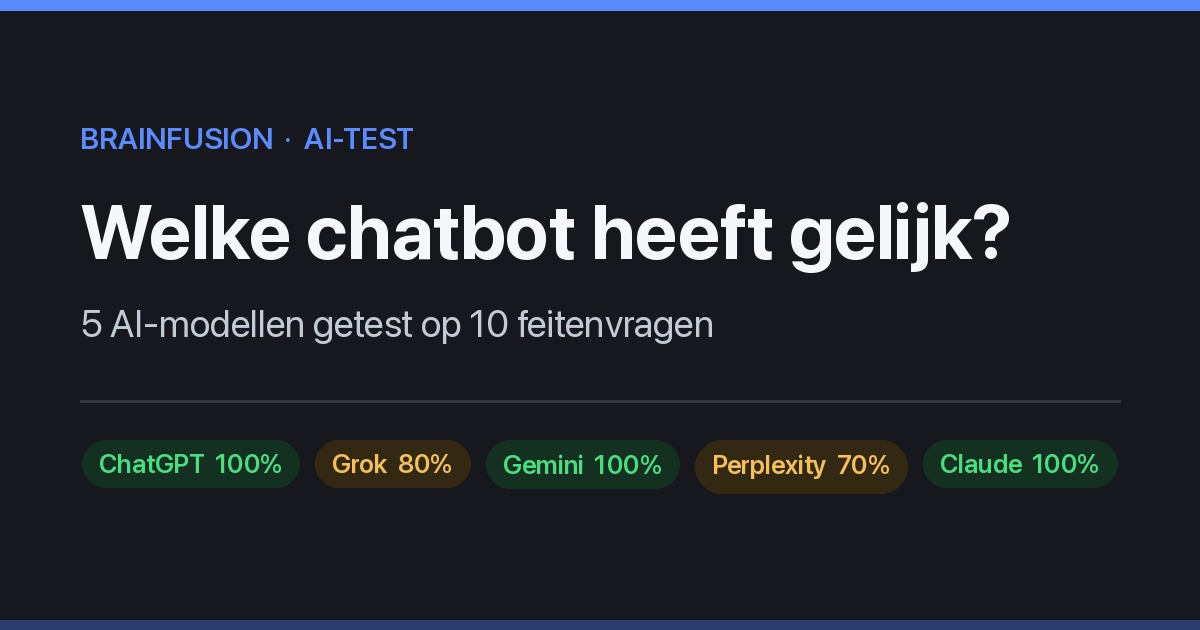
De uitslag in één oogopslag
| Vraag | ChatGPT 4o |
Grok 2024 |
Gemini 2.0 |
Perplexity Pro |
Claude Sonnet |
|---|---|---|---|---|---|
| 1. Kyoto Protocol — aantal landen & inwerkingtreding | ✓ | ✗ | ✓ | ✗ | ✓ |
| 2. Marie Curie — jaar & discipline 1e Nobelprijs | ✓ | ✓ | ✓ | ✓ | ✓ |
| 3. Gemiddelde afstand aarde–maan (km) | ✓ | ✓ | ✓ | ✓ | ✓ |
| 4. Top 3 landen met de meeste Nobelprijzen + aantallen | ✓ | ✓ | ✓ | ✗ | ✓ |
| 5. Oprichting Wikipedia — jaar & oprichters | ✓ | ✓ | ✓ | ✓ | ✓ |
| 6. Werknemers Google bij de IPO (2004, ongeveer) | ✓ | ✓ | ✓ | ✓ | ✓ |
| 7. Langste rivier ter wereld + lengte | ✓ | ✓ | ✓ | ✓ | ✓ |
| 8. Jaar eerste beklimming Mount Everest | ✓ | ✓ | ✓ | ✓ | ✓ |
| 9. Aantal manen van Jupiter | ✓ | ✗ | ✓ | ✗ | ✓ |
| 10. Bevolking van Nederland (recentste telling) | ✓ | ✓ | ✓ | ✓ | ✓ |
| Score | 100% | 80% | 100% | 70% | 100% |
Wat valt op?
Drie modellen gingen foutloos door de test: ChatGPT (4o), Gemini (2.0) en Claude (Sonnet 4.6) scoorden alle drie 10 van de 10 (100%).
Grok (2024) eindigde op 8/10 (80%) en Perplexity (Pro) op 7/10 (70%). Grok en Perplexity struikelden allebei over het Kyoto Protocol (vraag 1) en het aantal manen van Jupiter (vraag 9); Perplexity liet bovendien bij vraag 4 de gevraagde aantallen weg. Juist de vragen met een precies, in de tijd veranderend getal bleken het lastigst — de “tijdloze” feiten (rivieren, bergen, jaartallen) had iedereen goed.
🔍 Foutanalyse — klik voor de details
Vraag 1 — Kyoto Protocol
Juist: 192 partijen (191 landen + de EU), in werking getreden op 16 februari 2005.
✗ Grok: “84 landen” — fors te laag.
✗ Perplexity: “197 partijen” — te hoog.
Vraag 4 — Landen met de meeste Nobelprijzen
Juist: VS (~420), VK (~140), Duitsland (~115).
✗ Perplexity: noemde wél de juiste drie landen, maar gaf géén aantallen — antwoord onvolledig.
Vraag 9 — Manen van Jupiter
Juist: 95 bevestigde manen.
✗ Grok: “115” — te hoog.
✗ Perplexity: “79” — te laag.
De les? Voor harde feiten zijn de meeste topmodellen verrassend betrouwbaar — maar blindvaren op één chatbot blijft riskant, juist bij exacte aantallen die in de loop van de tijd veranderen. Een tweede bron checken loont nog steeds.
P.S. Deze post is 100% door Claude Code gemaakt terwijl de input door Claude Chat zijn gemaakt, dus de stelling “Wij van WC-Eend adviseren WC-Eend” is hier misschien ook wel aan de hand.
Als je dan toch tot het einde van deze post ben geraakt – als je dezelfde “uitgebreide vraag” herhalende keren aan dezelfde AI geeft ( gebruik iemand anders die het ook voor je wil testen ) dan zal je zien dat er bijna altijd een verschillend antwoord komt …